
KubeCon EU 2024 LondonのObjserivability Pipeline Query Language Sessionのre:capです。5/20 Kubernetes Meetup Tokyo Vo.70で話した内容です。
youtubeにセッション動画はすでに上がっています
Unix-based pipeline
入力のテキストファイルを処理するのに、使われている伝統的なパイプライン。現在でもログ処理なのに利用するケースがある
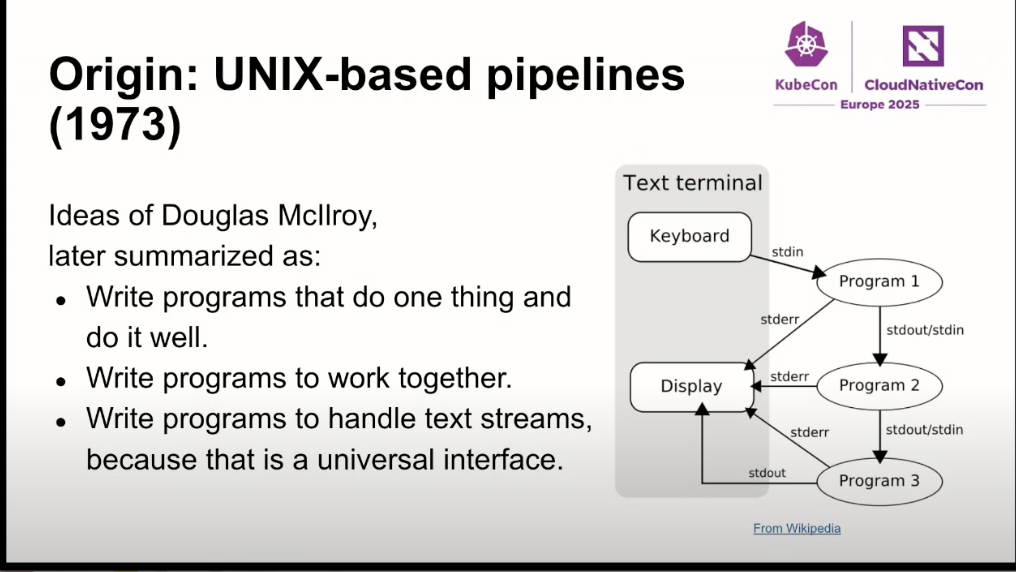
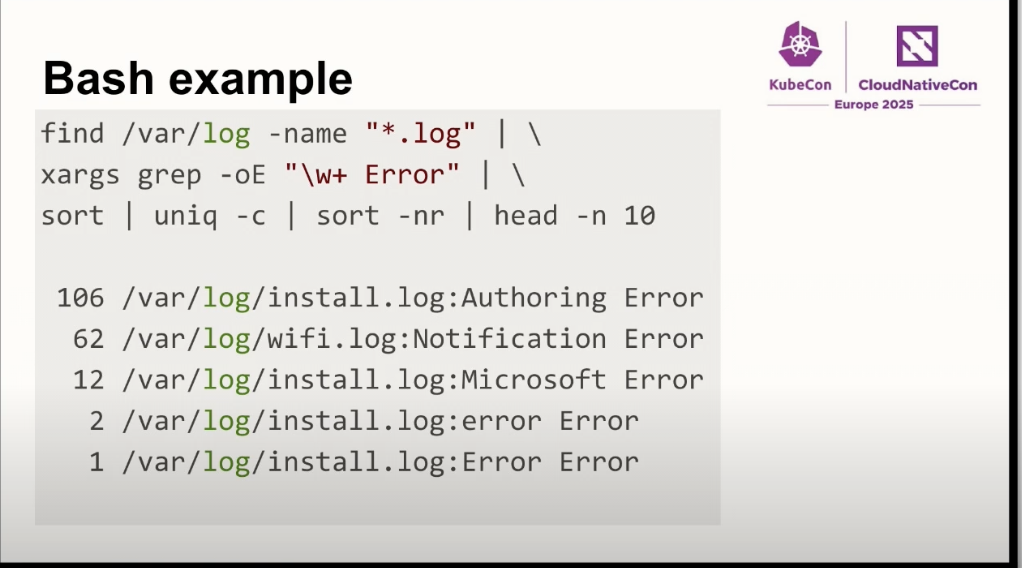
ログから、なんとかErrorを抽出してログ数をカウントするワンコマンドを、find、grep、sort、uniqをパイプで繋いでログ調査で利用する
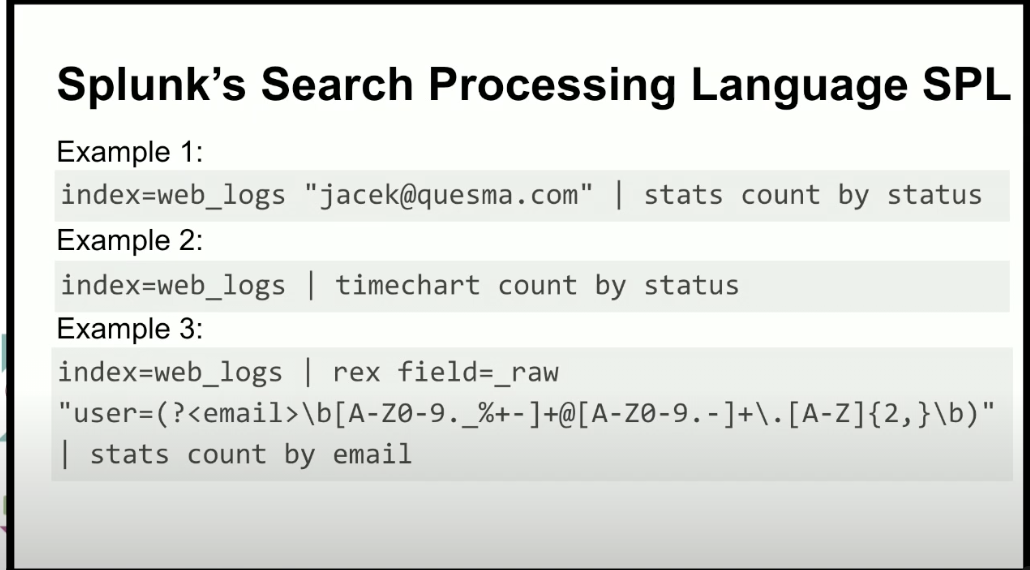
Spunk Search Processing Language SPL
クエリを宣言的に記載できる。グラフなどUIで見やすい
Prometheus
Prometheousのメリットとしては、同じpromQLで時系列のデータ推移を確認できる。ContainerだとStatelessワークロードが大多数を占めるので、動いているContainerが次々変わるので、サーバーに依存するような監視では対応仕切れなくなると考える。
時系列データを取り扱う、pull型でアプリケーションから値を取得するので、Zabbixなどに比べて負荷になりにくい
ツールの乱立
Splunk、Sumo Logic、Datadog Log Explorer、Elastic ESQLの例を上げて、それぞれのクエリによって、検索オプションが異なっていて、ベンダーロックインになる問題がある。

SQL
SQLへの回帰。近年だと、非構造されていないデータにも
データウェアハウスではSQLで主流

SQLのメリット
PromQLに比べると順番、フィルタのフローを持たないといけないが、サブクエリ

標準化について
完璧な仕様で標準化することは適切ではない。Open Telmetryも優れた収集実績があってことから誕生した
SQLは50年使い続けている技術でもあり、今後も生き残る。構文が最終的にどうなるかはわからなく、可観測データにアクセスできる単一の言語が求められていると最後に話されてました。