
BigQuery (BigQuery Geo Viz)を使って、Average Rent Percent Difference From Previous Yearの平均をDataprepでのデータマイニング
から、BigQuery Geo Vizへの可視化、BigQueryMLによる学習、推論まで書かれています。
https://medium.com/@williszhang/bigquery-gis-ml-on-government-open-data-2605ed9d2e8
ここでは、DataprepのReceipeについていくつかポイントを記載します。
extractpositions col: {Facility Address} type: last count: 6
Facility Addressに、”4733 BRADLEY BLVD CHEVY CHASE MD 20815″ と入っているが、
文字列のlast(最後末)を抜き出すときReceipe
Extract by positions
このfunctionsはスペースはカウントされないので、下記でトリムしてやる必要がある。
textformat col: zipcode type: trimwhitespace
filter type: custom rowType: single row: ISMISMATCHED(zipcode, ['Zipcode']) action: Delete
filter関数。vaildな値かどうかを判定して、rowを削除するかのアクションを設定することができる。
https://cloud.google.com/dataprep/docs/html/ISMISMATCHED-Function_57344747
このブログの例だと、Zip codeチェックに使用しています。
他にも、電話番号、E-Mail、クレジットカード、IPアドレス、URL、日付時間等のチェックができる。
Code Violations CSV. Wrangle recipe について
drop col: {Date Assigned}: Drop
としているが、BigQueryに登録するschemaで、Date_Assignedを指定しているので、Too many columneとなり怒られてしまう。
![]()
Code Violations CSV. Wrangle recipeから、”drop col: {Date Assigned}: Drop” をDelete(削除)することでbq loadできることは確認しています。
最終的にこんな感じになります。
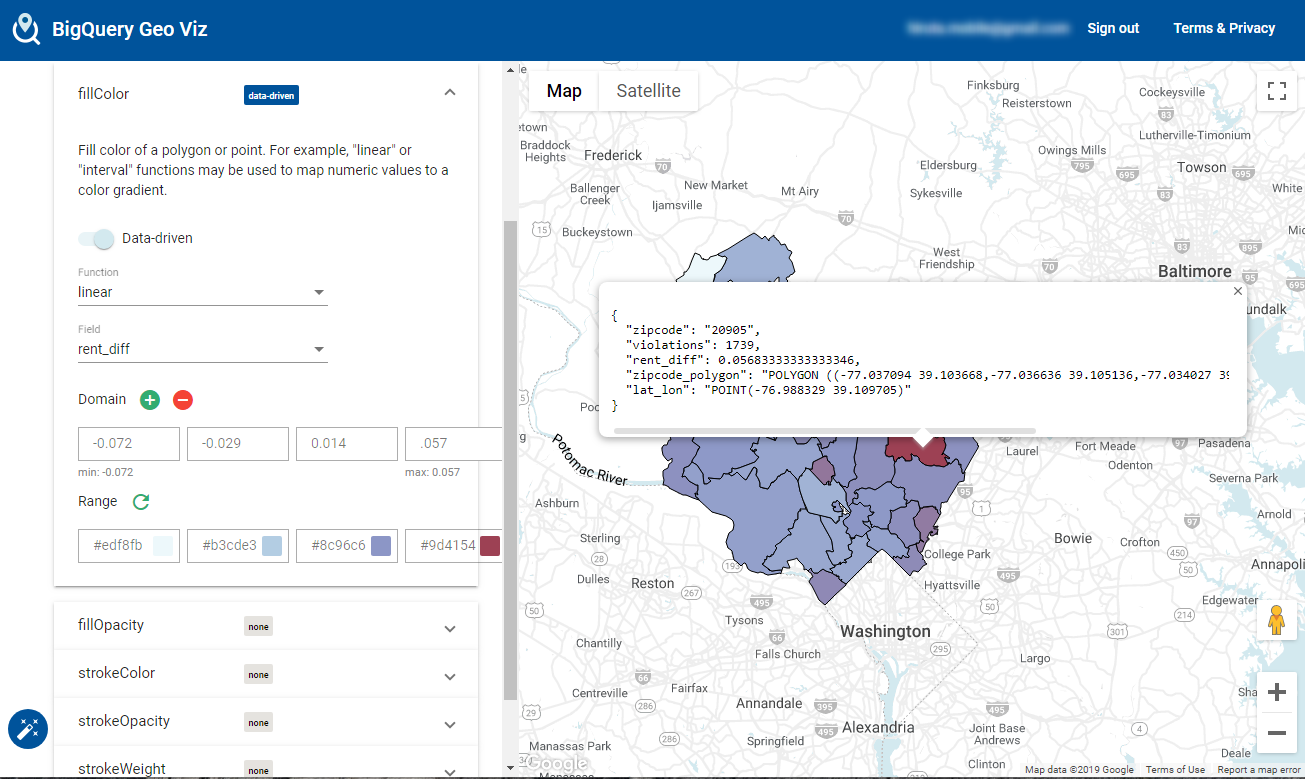
Dataprep ML学習させる前に、イレギュラーなデータを除去できるDataprepの有益性を改めて実感。