instance groupを使う場合、instance templateが必要になり、なんらかでinstance templateの更新が必要になった場合、インスタンスの再立ち上げなり必要になります。今回試したのが、無停止でインスタンスの更新を行えるRolling Updateになります。
https://cloud.google.com/compute/docs/instance-groups/manager/
変更前のインスタンステンプレートを作成します。
gcloud compute instance-templates create demo-instance-template-1 --machine-type n1-standard-1 --network product-network --maintenance-policy MIGRATE --scopes "https://www.googleapis.com/auth/compute" "https://www.googleapis.com/auth/devstorage.read_write" "https://www.googleapis.com/auth/bigquery" "https://www.googleapis.com/auth/sqlservice.admin" "https://www.googleapis.com/auth/logging.write" --image centos-7 --boot-disk-type pd-standard --metadata startup-script-url=gs://h-private-auto/startup_demo.sh --boot-disk-device-name demo-instance-template-1
インスタンスグループを作成します。
gcloud preview managed-instance-groups --zone asia-east1-a create demo-instance-group-1 --base-instance-name demo-instance-group-1 --template demo-instance-template-1 --size 2
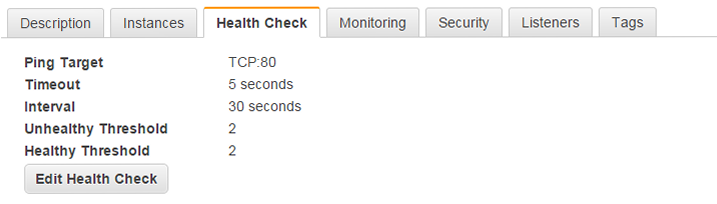
HTTPロードバランサーのためのヘルスチェックを作成します。
gcloud compute http-health-checks create "demo-health-check" --port "80" --request-path "/index.html" --check-interval "5" --timeout "5" --unhealthy-threshold "2" --healthy-threshold "2"
HTTPロードバランサーを作成しておきます。
gcloud preview instance-groups --zone asia-east1-a add-service demo-instance-group-1 --port 80 --service http
gcloud compute backend-services create demo-web-service --http-health-check demo-health-check
gcloud compute backend-services add-backend demo-web-service --group demo-instance-group-1 --zone asia-east1-a
gcloud compute url-maps create demo-web-map --default-service demo-web-service
gcloud compute target-http-proxies create demo-web-proxy --url-map demo-web-map
gcloud compute forwarding-rules create http-rule --global \
--target-http-proxy demo-web-proxy --port-range 80
ロードバランサにExternal IP (グローバルIPアドレス)が割り当てられます。
変更後のインスタンステンプレートのためのstartup scriptを作成します。
#! /bin/bash timedatectl set-timezone Asia/Tokyo PRIVATE_IP=`curl "http://metadata.google.internal/computeMetadata/v1/instance/network-interfaces/0/ip" -H "Metadata-Flavor: Google"` INSTANCE_ID=`curl -s http://metadata.google.internal/computeMetadata/v1/instance/hostname -H "Metadata-Flavor: Google" | cut -d "." -f 1` yum -y install httpd service httpd start cat >/var/www/html/index.html <<EOF renew $INSTANCE_ID EOF
変更後のインスタンステンプレートを作成します。
gcloud compute instance-templates create demo-instance-template-2 --machine-type n1-standard-1 --network product-network --maintenance-policy MIGRATE --scopes "https://www.googleapis.com/auth/compute" "https://www.googleapis.com/auth/devstorage.read_write" "https://www.googleapis.com/auth/bigquery" "https://www.googleapis.com/auth/sqlservice.admin" "https://www.googleapis.com/auth/logging.write" --image centos-7 --boot-disk-type pd-standard --metadata startup-script-url=gs://h-private-auto/startup_demo_2.sh --boot-disk-device-name demo-instance-template-2
set-templateでインスタンステンプレートを変更することも可能ですが、こちらだとインスタンスは自動では変更になりません。
gcloud preview managed-instance-groups --zone asia-east1-a set-template demo-instance-group-1 --template demo-instance-template-1
インスタンステンプレートのローリングアップデートを行うには、下記のようにします。インスタンスが起動立ち上がってくる時間を考慮する必要があるので、–min-instance-update-timeオプションを指定しています。(このオプションを指定しないと片方のインスタンスが準備ができる前にもう片方のインスタンスの更新が始まり、Server Errorが起きました)
gcloud preview rolling-updates --zone asia-east1-a start --group demo-instance-group-1 --template demo-instance-template-2 --min-instance-update-time 360s
5秒間隔でcurlコマンドにてhttpアクセスを定期的にしましたが、アクセスエラーを起こすことなくインスタンステンプレートの更新が行えました。※AWSのAutoScalingでは実現されていない機能。AWSでは、ElasticBeanstalkを使うことでRolling Updateが可能のようです。

Instance Group Update ServiceのAlpha versionでも将来仕様が変更になる場合があるかもしれません。