what we’re doing here is we’re actually building like we said more reliable systems out of less reliable Parts. So this means the bottom of the pyramid has fewer nines than the top.
All of the VMS that are running that system have two ninths. All right, the discs that that are running that are holding your data for Gmail have one night.
One region tends to fail at a time, so if you use two zones, This one has 99.9. This one has 99.99. They’re a different set of 99.9. Right. So it’s very unlikely that they will both fail at the same time. So this means that when a failure happens in one of the zones you can just run away, you do not have to debug it.
We’ll be talking today about Managing life cycle of the operating systems in a deterministic way.
Imagine resolving all the dependencies for packages downloading. All of these packages and deploying them onto the host would take enormous amount of time. What we are proposing is changing to this mechanism which sudendra is going to work.
Recording in progress. Awesome. Hey everyone. Welcome. I know more folks will be joining but we only get silent. We had a tight schedule.
Yo, welcome to welcome back into Tiny B's practice. Public data launch webinar. My name is kanyan and I'll lead a tiny B park mctavia. I'll be host for today's session.
Dollars e. And I will cover a few slides about the Innovations that we have in this launch and do a part-time. After the launch part is done, we will have a panel discussion. Painfuls from AW News to Lama index and pink cap. They will go into how to use this air Technologies.
Specifically Vector search to build some commercially viable applications. Uh after that we'll have another demo going to details of one such interesting use case and with that I will conclude the session. Forget that, let me hand it up to Shen, then please take it away. So yeah, welcome everyone.
Uh, I'm Xing and I hope you can hear me clearly. I'm the product manager of Thai DB cloud and AI today. I'm excited to share a significant leap forward in our database technology. The public battle for our KDB sectors vectors search. This is not just a new feature. It's a transformation bringing together AI at the most advanced distributed database in a seamless.
Powerful way. So let's first talk about why we are doing Market search in tidy B. So in today's generative, AI Technologies, we are driving a demand of advised data, handling capabilities, every day every organization and an every large language model is generating and processing, vast amounts of the data, either extraordinary space, the challenge of many organizations managing this search efficiency, ensuring quick access analysis and the ability to scale or demand all at a lower cost kind of select research addresses.
This need by providing a unified database solution that simplifies your Tech stack by handling, both traditional and Ai workloads, this eliminates the need for separate systems to handle different types of data operations, reducing the capacity, and the enhancing the performance plus Thai device architecture. Reassures that your data grows whether in volume velocity or variety your systems.
Perform a skills. You effortlessly. This is crucial for pieces that you that needs to stay competitive in today's fast pacing generative, AI market, furthermore, our SQL compatible Vector, search leverage, your existing SQL expertise to seamless integrate your business. With AI or vector functionalities. This is not just a simplifies, the learning curve, but also empowers your teams, your, your Engineers, your, you know, dpas to perform sophisticated data or operations using familiar tools.
Let's have a quick gallon of the technical part of our Innovation. Thai DB introduces new Vector, search marketer data type and this and the similarity search. Indexes enabling you to store data the victory values together. Seamlessly thinking about a real generative, AI chatbot development. You can just leverage tidy, B, to store your operational data, document data Knowledge Graph and messages store C plus Vector data data.
Search Vector data in just one database, these capabilities can efficiently. Simplifies the capacity data, you know, operations and enable you just focusing on the value of your data. Furthermore, Thai DB Soaker search build on half of our native columnar storage architecture which is tidbit another famous open source project by Pinkard.
This ensures racket search performance in essential social. Real-Time demands for modern UR applications. This design, not only boosts the efficiency, but also significantly improve the query execution speed allowing, you just, you know, building applications figuring out data inside faster and more reliable. Um, so actually uh, before our public beta.
Uh, in March, we launched the private battle of the high DB vector search. So, over the past three months, we have seen an incredible engagement more than 600 users from a diverse range of Industries. Have joined us bringing their valuable unique perspectives and feedback to us to the product team, to the, to our community.
We heard how Thai DBS. 01 AI solution, could simplify their technology stacks making their backend management. Back-end service is more straightforward and streamlined. All the operational machine work are less consuming. This Simplicity brings the power raised the power of the Thai. DB also brings lower costs for their long-term solution, allowing our developers focusing more on Up in The Cutting Edge generative, AI applications with a familiar SQL interfaces without getting into the, you know, super complicated data management tasks.
So, this is actually what we heard from our users. The database you need is the database. You are using is the best Vector database. And this is also the commitment from us at idv. At Inca our Innovation, uh, and the powerful capabilities of our market search technology making idb the one choice for your business in the year of AI.
So, With that, let me put this into some of the uh, you know real demo practices. Um, so uh, let me share my screen, uh, with the our Cloud management portal. So, assume you are a new user coming to a tinydb, you just type, you know, iredbcloud.com, you will be, uh, you know, direct to this signal page.
I will just sign up with my Google account. I clicked my account. And it's just in a few seconds. Uh you will be assigned a new entire DB service cluster and inside this cluster uh you know there are multiple functionalities for you to navigate to learn about the Thai DB and build, you know, regular uh you know uh applications or generative AI applications with the vector search.
So as a developer, my first step is definitely to connect my database. So here you can see uh, you know, we support different types of drivers, clients for you to connect to, but today I'm going to do a demo. We're seeing uh, you know, the Google collab. Is a notebook.
So, the tasks I'm going to perform here is to, you know, input, some of the, uh, you know, text data, convert them to embeddings and later using Vector, search to figure out the answer, uh, for semantic search answers result, uh, for my questions. So I'm zooming a little bit so that the font size will be bigger.
So you can see uh, in Google Cloud. Uh, you know, I have to say, for everyone's time, I have already, put some of the secrets here uh, to really connect that, uh, you need to install those libraries, you have to, you know, uh, put the database connection streams with username password and everything.
And uh and at that we'll uh give you the permission to connect. So here, I guess I'm not initialized the notebook. Uh, it takes some time to you know uh install all the drivers. While I'm doing that, I'm going to recreate the connection and copy paste, the data into the Into the secret part.
So I'm going to you know, regenerate the password and put it here. And also the rest of the part, you can see the DB name, the Thai DB, host the part, and the username, and to save everyone's time, already put it here. You can simply copy paste and just make it happen.
Uh so to make the connection work, uh, you just need to put all the environmental variables reading from the secrets and it should be. Okay. So the next part I'm actually reaching out to the open AI uh to do the embeddings, you can see from the code, I'm using the embedded model here and I'm going to use W with some of the parameters as the L2 distance to generate the older embedules.
I initialized the model and next steps I'm going to, you know, use the model to generate, you know, the embeddings from that. And with that if I run the queries here, I can actually get the answer from open a client. The the questions I'm asking what is high degree?
You can see from the content, I actually put some raw text, IB, content, ikv, content, PD content, those are the three essential parts of our database, you know, from the technology perspective. But if you are searching, what is IDB. If I run the vary, you can see a tin DB is the open source GDC, SQL SQL database.
That's actually the content from the, you know, the the, the, the embedding the raw content. So we start, if I'm going back to my SQL editor, if I'm going to, you know, retrieve the database, uh, you know, the Database record from here. We just you know got some of the table and and with the ID content and the vectoring values here.
If I run the query, I actually run the, you know, Paris and local multiple times. You can see, I have several similar content. It shows the uh, you know, the actual content the embedding data. So the really powerful part is like your traditional data, your structure data, your content.
And the vector, the vector, the embeddings are in the same, you know, table. And your data is much closer, you don't need to manage the multiple systems and everything in just one table. You can easily, you know, retrieve those data processing, those data, build your applications, with really similar six spheres.
So that's just a quick. Hello world of the vector search. And today, we have already have this feature back, public beta on all our Adults regions on IDP servers. So, no matter URL existing 3db service. Customer or you are creating a new account, just coming in to this page and and we have the tutorials building how to let you learn how to use, you know, prefer language being the rich amount of the generative patients.
You have all start here. I just click the button, uh, with all the samples and the tutorials to help you to get started. So, yeah, that's uh, just uh, you know, a quick guidance of the functionality with very simple worker search. So, with that, I'm going to hand over to Kalyanne to talk about what we are also doing in this market.
Awesome. Thank you. Uh, welcome again. So tidy B is more than just practices, right? Why. Because billing applications requires a lot more and we get that, that's why we have been actively partnering with key vendors and players in the AI ecosystem. To bring you a comprehensive solution. So the cluster product native support for big names like AWS and lavline notes, tidally integrates all the foundational language processing tools that you would Whether it's llms chat engines, hosting tools or rag in application development Frameworks or even user experience tools.
So what this means is, you can focus on developing amazing AI applications without worrying about the back-end complexity, similar to the feedback that you've seen from our private data, our Caribbean simplifies the process and accelerates your work. Then, if you go to the next slide, Uh we're reaching the end of the presentation here, so before launching back to search, we did two things.
Internally One, we looked at our mission, right? Our mission is to make the lives of our developers easy. So that is the lens. We have kept rented Center in the development of this capability. Second thing we have done is we have dog food at this app, a lot and used it to actually build a public pacing rag-based chatbot that you'll actually see in the later part of the webinar to improve the developer experience.
Only then we felt good about launching this publicly and making sure you as developers can get to use it. And yeah, see what you can tell. So, uh, with this launch, we've also seamlessly combine, the benefits of cardi B into making practice just scalable and optimate cost efficient right.
First of all, tiny is known for its elastic and infinite scalable nature, right? This is pretty ideal from AI workloads. That can expand at an instant. So that's awesome. Second thing is we have a great Fleet here that chin only showed it is. Perfect for audio. Early needs to try and experience before you actually come back.
The third thing is the fact that nav's open source as always, amazing your indications, And most importantly, the MySQL compatibility, these are all chains on top. Well, hope that got you interested in, trying out theory practices public data. And if you're interested, this is the link and the website is there.
If you want you will get, you can get this tag later too. So by scanning, the according to connect the page to sign up and start your business. Hope you have enjoyed the presentation, as well as the demo now as the time panel, right? So just before we dive into the panel, as we transition to this thing, Uh, we thought of addressing one the main common challenge that development could face, right.
Like you have likely heard a lot about all the latest Innovations in AI and back to search from bunch of vendors. But one thing that we have constantly heard in the pressing question, that that remains is how and where can use these Technologies effectively to put them into right use.
And that's what we want to use. Today's discussion, it aims to it's that Gap. We want to move beyond the theoretical and explore like real world occupations that are not only Innovative but also commercially viable. So our expert Palace from AWS Lama index and Think that will share their insights and experiences highlighting practical use cases and such stories.
We'll also delve into how vector search can transform your AL applications and where the industries are the right for Innovations on. So, with that background, let me start. Pay coming from your position that AWS. You've probably seen a tons of customers Partners. Developers doing some interesting applications with the zit countries, right?
So you want to share some of the interesting ones that you've seen. Yes, for sure. Um, actually a little bit of background what I'm working on and Uh who um I am interacting with. So basically I I came from the So should I get that background? And now I'm working with partners, and customers building applications around data and AI.
So let me actually start from internally within AWS or amazon.com. We know amazon.com is an early adopter of Technologies, like jnai. Probably at that time. We don't even call it genai. But we know on our amazon.com website, their Technologies on reviews and probably labelings. We are already adopting that and within AWS our solution, architects and software, developers are proactively developing tools to improve internal operational process and productivity.
Search use cases as like chat box, search knowledge, bases, coding writing and learning docs Etc. Um, I can share some of our publicly referenced Customers and partners success stories. A lonely Planet is a premier travel media company that tested multiple genai Solutions vendors and found AWS Bedrock to be 78.
More cost effective in their, travel use cases further to that, they were able to generate experiences and itineraries at 80 less the cost of manual creating them. So that is a really successful story. I believe most of our audience have heard of that at our reinvent last year. Um like I said, I'm currently working with our partners Building Solutions around data and AI.
I can share a story of a partners that I work close with. Our partner named publicist Sapien. They have a genai solution, which is public listed called, ask Bondi, it's hosted on AWS. So it's one of a groundbreaking solutions to power gen Ai and let their customers to deploy use cases in a matter of days or weeks from understanding, from the starting point.
So, customers can really focus on their business, differentiated applications as opposed to deal with a lot of like manual overhead. So there are some of the the stories of their success story with their end customers because our partners are Uh, working. With customers deliver values. Faster, they work for a global farmer pharmaceutical company, creating personalized, marketing content, and skill and deploying the first use case within just two weeks.
And they also worked with a North America retailer. Rewriting product descriptions to drive increased engagement using existing product details customer reviews and brand guidelines and tons of highlighting the most important product features. They also worked with uh, invest investment advisor. They quickly identify products and services to recommend to customers with multiple retrieval.
Augmented, Enterprise search solution, basically, from a very sophisticated knowledge base, so we can see customers Up and our partners and also internally within AWS. We are innovating at a speed that we haven't seen before. So definitely I would say a technology that changing the the world
I think I'll be able to call you. Sorry, that's right. My bad. Thanks for Uh, learning now to you before we dive into some of the interesting applications and so on, right? Like a lot of my index has been at the Four Point of the EA Landscape. We've seen all the things.
So the one thing that we have been getting a lot is retrieval augmented generation and how it's gaining a lot of popularity. So first of all, for maybe just can't set the context initially briefly, what it is and what folders Lama and explain it. Excuse me. Um, Still retrieval.
Augmented generation is a solution to a bunch of problems when trying to get. Llms to answer questions about data. Um, The fundamental problem is that obviously llms are trained on a mountain of data, but they're not trained on your data. You the thing that you want to, uh, Answer questions about is the is the data that lives in your company.
Uh, and that data lives in databases. It lives in unstructured files. It lives in. You know, power points and PDFs and slack messages. Um, So fundamentally. If you want to be able to answer questions about that, you have to give that information to an lln. Um, you could try doing it by fine-tuning, an LLM with your data.
Um, but that is uh slow and expensive. And you're not going to be able to uh, you know, refine-tune your model every day to keep up with the new data that you're adding to your database. Uh, so you need a real-time solution and rag provides that solution. What you do in retrieval augmented generation?
Is you first look for data that is relevant to your query and you provide that to the lmm Um an obvious question is you know, if we've got company data? Why don't we give all of our company data to the LR? The answer is if it's just too expensive to do that every single time you have, you know, the average llm has Uh, a, you know, a token when an input token window of Uh, you know, maybe a hundred thousand tokens right now, but you probably have tens of millions of tokens worth of data in your company.
So it couldn't possibly fit into the context window and even if you had an infinite context window, you wouldn't want to because you'd be uploading all of this irrelevant data. Every single time to answer. What might be a very simple question. Um, So instead what you do is you use Vector search, you use, uh you use an embedding model to turn your data into numbers Uh, and then you can use Uh, the same embedding model to turn your query into numbers.
You put all of those numbers into a big database and you can use relatively simple, mathematical operations to locate numbers that are close to each other in the vector space. Um, that is the fundamental Insight. That led to retrieval augmented generations that you could use vector search in this way to search by meaning rather than by keyword.
Um, So, like I said, Retrievalignant degeneration, it sells the limited context window problem it solves real-time data. It allows for attribution because you know that the context that you provided To the other line was this, you know, particular set of documents just before the question was answered. So, you know, the answer is that those documents?
Uh, which can be a big part of The solution. Um, and finally There's accuracy. Um, you are avoiding hallucinations. Um, simply by using this technique by giving the giving the llm your data at the time of the query and saying, use this data that I just gave you and only
前回都合により、Anthropic の方がビデオ登壇になってしまいましたが、AWS Summit Japanのために来日の際に再度Anthropic Claude nightを開催されました。
Anthropic キーノート&デモ
@YoMaggieVo @alexalbert__
文字起こししたもの
Hopefully, everyone can hear me from back there. I'm going to move this a little bit. Okay. Okay. Um, okay. Okay, great. Uh,
Um, this because, um,
Uh, to begin with. Um, Uh, I'm here with also Alex, Albert, who is the head of our developer relations, um, the head over to developer relations, uh, motions right now, and he will be speaking with later.
So I'm sure many of you have heard of anthropics before, so I will go directly into quad 3. I'm talking about our models. Today, we'll be talking about both vision and Tool, use mostly
To begin with. Here's an overview of the claw 3 model family. It consists of three large models. And the first one is uh Opus which is our largest most capable model. Then we also have sonnet, which is our middle, balanced model, and then we have haiku, which is our fastest and smallest model,
And you can see it in the chart on the left, that they're also spread across different cost tubes, and so, when you select a model, it's important to think about the kind of the model that can do, all the things you need it to do. Without, you know, breaking the bank and being exactly the price point that works for you.
A brief overview of the things that Claude can do. I think can be broken into three major categories, the the Category is about analysis. So all three models in the cloud 3 family are incredibly capable at high level, extremely nuanced analysis. On things like analyzing large sets of documents.
Large sets of emails, different databases of both code and text and so on.
The second major category of what plot is capable of is in the area of content generation and just general knowledge. So Claude is able to do things like help you generate marketing, copy and other types of business content, As well as be a really effective chat bot for things like product support or just helping you brainstorm your ideas or how to do something better.
Claude's a really good assistant to just help you think through things.
And the last area which uh, we think is the most exciting area going forward, is in the area of automation. So, with tool use, you're able to start automating end-to-end workflows so that Claude can do a series of tasks without you having to handle every step of the process.
We believe that this is going to be kind of more increasingly important for businesses and startups, going forward and more of a way that people use models going forward as well.
Claw 3 is able to do this with a series of improvements from previous models.
The first areas are that. It's just faster all around. So you're able to do things like chain a bunch of tools without having it hurt your latency, as much as it would if you were using older models,
And it's also much more steerable. Meaning you can do a lot more with little prompting or little prompting optimization. You can write shorter prompts to get more performance in Behavior than before.
Furthermore. Um, Claude is also much more accurate and trustworthy than previous generations meaning, for example, that Claude can Utilize more accurately information all across the context window.
We've also worked to further lower hallucination rates and to generally make you make the model both more trustworthy in terms of its performance as well, as give you tools like better citations to be able to understand and verify what the model is doing.
Then lastly excitingly all of the models in the cloud3 family have Vision capabilities, meaning that now Claude can understand images as well as text.
Going forward, I'm going to talk a little bit about our vision capabilities. Now what you can do with it as well, so there is An overview is that our vision capabilities have been specifically trained for business, type use cases. Meaning that it understands charts graphs. Technical diagrams, the kinds of things you would see a lot in business settings.
De Masco cono casanisms.
Um, let's if you can see the series on the right. There's a bunch of examples of us, kind of what this means, Claude is able to understand the conditions of items for insurance purposes or it's able to extract data from charts and graphs and then write code about analyzing that information.
It's even able to transcribe handwriting
We're very excited and grateful to have a close relationship with Amazon in Japan, especially meaning that we've been able to get feedback on our models and how well our models perform in Japanese.
That means that we do understand that our current models have some gaps. There is like claudice Claude, 3 as it curly is is not able to read um you know, extremely messy Japanese handwriting for example or um you know certain kanji that are really rare and older and so we're working on making that better for future models.
I'm going to give you a few tips right now on how to properly use Vision. Uh, these are the three main ones that I think will help you a lot.
The first one is to put your images right at the top just like you would with documents with Claude you should put your images at the top before your instructions before your query so that Claude can have that image as context to understand the rest of your instructions.
You should also label your images. So here I've labeled them just image one through four in my example but whatever label you give it this allows you to better reference it in your instructions the different images as well as gives Clauda understanding of what the order of these images or maybe even what those images are if you name them.
And then in general for images that contain information, you may want to make it a two-step process where your first step is just to ask Claude to extract the information. So the numbers from the charts or You know, certain Things that it can see in the image before asking it to do a task with that information.
So now I'm going to show you a video of an example of how Claude is able to extract. A lot of information at very fast speeds from documents that are messy. And some of the, the images are, you know, hard to understand and hard to read.
I think. Do I just play and step aside?
Okay, go ahead. I have no introduction. Just in English. Do I play it with sound or no. Uh, can you reduce the sound? Yes, but it'll be in English. Okay, let me Go back for a second.
Make it up. Please play with English. Okay. Do I pause for them to translate? Okay. In the world, to demonstrate this, we're going to read through thousands of scanned, documents in a matter of minutes. The Library of Congress Federal writers project is a collection of thousands of scanned transcripts from interviews during the Great Depression.
This is a gold, mine of incredible narratives and real life Heroes, but it's locked away in hard to access scans and transcripts. Imagine you're a documentary filmmaker or journalist, how can you dig through these thousands of messy documents to find the best source material for your research without reading them all yourself?
Since these documents are scanned images, we can't feed them into a text on the llm. And these scans are messy enough that they'd be a challenge for most dedicated OCR software. But luckily Haiku is natively Vision capable and can use surrounding text to tempt transcribe these images and really understand what's going on.
We can also go beyond simple transcription for each interview and ask Haiku to generate structured, Json output, with metadata like title date keywords, but also use some creativity and judgment to assess how compelling a documentary the story and characters would be We can process each document in parallel for performance and with Claude's high availability API, do that at massive, scale for hundreds or thousands of documents.
Let's take a look at some of that structured output. Haiku was able to not just transcribe but pull out creative things like keywords. We've transformed this collection of many, many scams into Rich. Keyword structured data. Imagine to put any organization with a knowledge base of scanned documents like a traditional publisher Healthcare provider or Law Firm can do Haiku can parse their extensive archives and bodies of work.
We'd love for you to try it out and see what we built. So, in that demo, you can see that Haiku especially can read documents extremely quickly. This video is slower than how fast Haiku is now, where now we make demos? Now we have to slow down the video just to see it properly generated.
Some other examples I want to show you. Here is an image of a whiteboard where the text is in cursive. It's hard to understand and read. And the image itself is also on a very reflective surface. Esto cochina.
I'm asking you to transcribe that content into, uh, Json, schema. And I'm not giving it this game. I'm asking it to come up with a schema that makes sense. Given the information
And you can see that as a result, Claude not only transcribes, it perfectly even the capital letters Uh, but also that Claude is able to pick a Json. Schema that makes sense with the information architecture of the Whiteboard.
The coolest part of this I think is that Claude is able to pull out the very last line of both sides of the Whiteboard. To understand that it's not part of the list above it. So in the Json schema which will give you these slides so you can see it for yourself.
Claude is also separating that from the rest of the list in its results.
I have another demo. I wanted to show you where I want to get to full use in time. So I'm going to show you just the last part of it again. I'll give you these slides so you can see them later.
So the previous slides, I asked Claude to just analyze the picture of this shoe and to come up with information within a given Json schema.
But in this example I am not giving Claude a Json schema up again I'm asking Claude to just write out everything that it can confidently infer from just looking at the image alone. I'm testing cloths, analytical capabilities.
And you can see that in the results, Claude is able to pull out the brand of the shoe, the colors, but also things like the materials and how it has a reflective kind of silver, detail in the back, for example.
Claude is even able to tell that the shoe is made for running on Trails and what kind of terrain such as gravel and dirt.
So I'm excited to see what you guys can do with vision. I think it's, you know, a state of the art in many ways and one of the most Capability. Unlocking areas of the cloth 3 family. Acadero.
So now let's talk about agents and tool use
For those of you who don't know what agents are, it looks a little bit like this.
Quad three especially has really improved agentic capabilities from previous models.
So in this example I have you can see that given a specific user request such as asking for reimbursement for blood pressure medication. Claude is able to analyze the user's goals and then complete a series of tasks that ends in either giving the reimbursement or saying something else that helps the user further along.
You can see that in the list of tasks that Claude is completing there are things like pulling the customer records and running drug interaction. Safety checks, these are all things that Claude can do with toy use. Que con company.
So you can create agent workflows with tool, use and Tool use is really simple under the hood.
It basically consists of a user prompt or a question as well as a list of tools that you've given Claude. And the tools need to just have a name, a description of what the tool is and then all the parameters that you would need to run that tool. De company.
And then you gave all that to Claude. And Claude is able to analyze the question. And then choose the right tool for the situation. So in my example, my question is, what is the final score of the yomiyori Giants game on June 16th 2024 just two days ago.
I'm asking this question because toll use is a really good way to update Clause information when you need to find out information after the training date cut off. So Claude was not trained two days ago. Meaning Claude doesn't actually know this information.
And God is able to in the on the right side of the slide, you can see that quad would pick not only the right tool but also be able to extract the various parameters of the information from the various parameters such as the name of the team as well as the date of the game.
Here's another example, that shows you what you need to do to have successful tool use
In this example, I have three different tools to look up in inventory information, to generate an invoice or to send an email.
And all of these are attached to various functions in your code. So looking up an inventory requires that you query a database or sending an email requires that you connect to an email API.
Claude doesn't have any tools of its own and it doesn't run any of these tools. So you have to write all these functions, and you also have to run them on Claude's behalf.
This allows you much finer control over the types of tools that you create instead of relying on, you know, any simple ones that we might make that aren't fulfilling your specific needs and use cases.
In my next example, I'm going to show you a detailed walkthrough of What it looks like when you call a tool and return the information to Claude,
I'm gonna begin by having a user. Ask a question, like, how many shares of General Motors can I buy with 500? This information is not available in Cloud's trading data, because stock information changes all the time. De Coco de no news.
Paul looks at that question and it knows it has a gen as get stock price tool that we've given it and so it's going to ask you to call the tool. That's what Claude is outputting.
Then when you get information, it's your job to Caught your uh query the stock market API with the information that Claude asked you for and then get that information back and then you can send to Claudid in the next part of the conversation. Um, the results of the tool call.
And then Claude is able to use that information in order to generate an answer for the user. In this case, doing some simple math, to tell the user that they can buy about 11 shares of General Motors at this time with 500.
So you might also know that there's something called agents for Amazon Bedrock, and I want to tell you a little bit about what that is and how that's different and similar to tool used directly with Claude.
So, in the middle, you can see the things that they have in common. The first being well, the series of them being that you can Define the tools. Claude is still able to request what tools to use and you still have to run those tools on your side uh and provide the information to close.
You're also able to see Claude's train of thought as to why it chose the tool and all that in both. The agents frames on Bedrock as well as tool used with anthropic directly.
Then separately outside of that. You have the ability to do Json mode. Which is when you have clogged return, every single tool call that Claude asks you for, Claude will give you the information in a Json schema. So you can use this to your advantage as a, you know, Surefire way to return Json information in Json mode.
You can also force toll use meaning that you can require a claw to definitely use a tool, either a specific tool or one that you gave it from a list of tools.
These more advanced features are capable because with using tool use with anthropic, you're able to see every single step of the process which allows you to take advantage of Json mode or Force tool use.
On top of this, there is agents frames on Bedrock. And what agents does is it builds a layer on top of tool use to abstract away The tool use syntax and structure, which allows you to get started a lot more quickly and easily. But also, you'll have a little bit less finer control over the process.
So with all this being said, I have a few demos to show you and then we can close out the keynote.
And uh, the first one is about a very simple way to use Two used with Claude for customer support.
Mero der, son lyrics.
Then the next demo, I'm going to show you. Is. Using a claw 3 to search the web and find a Find the, the fastest, uh, algorithm of a certain type using orchestration of haiku
Should I know. I don't want you to know it's scary, told you one of this. Sub agent orchestration is when you have a more capable model like, Opus, Call on and write prompts for. A smaller model like haikune in this case is going to do that a hundred times in parallel.
De gusta es me con la es.
So the last time I want to show you is, how you can do this with vision as well.
In this demo, we're given Claude some tools to browse the web. Um, as well as to run the code that it writes and the ability to call on some sub agents. So in this case, Opus will call on haiku
Res Más.
I think the coolest part of this demo is how if you give Claude the ability to run and understand the code that it can uh reason with why it made the mistake and then fix the code and make it better without you having to debug it yourself.
So I have a bunch of useful resources that I will leave you with and we will be notice that and I will give you the slides so that you can see all the different resources here as to how you can. Also, uh, Kind of do more exciting and more advanced work with Claude.
The state on a home. And, With that. Thank you. Thank you so much.
“Claude is also much more accurate and trustworthy than previous generations meaning, for example, that Claude can Utilize more accurately information all across the context window.”
“We believe that this is going to be kind of more increasingly important for businesses and startups, going forward and more of a way that people use models going forward as well.”
“The coolest part of this I think is that Claude is able to pull out the very last line of both sides of the Whiteboard. To understand that it’s not part of the list above it.”
“Claude doesn’t have any tools of its own and it doesn’t run any of these tools. So you have to write all these functions, and you also have to run them on Claude’s behalf.”
“I think the coolest part of this demo is how if you give Claude the ability to run and understand the code that it can uh reason with why it made the mistake and then fix the code and make it better without you having to debug it yourself.”
Error raised by bedrock service: Did not find region_name, please add an environment variable `AWS_DEFAULT_REGION` which contains it, or pass `region_name` as a named parameter. (type=value_error)
第4章 社内文書検索!RAGアプリを作ってみよう
ベクターデータベースの話から、Agent for knowledge Base、Langchain ( LCEL )での実装方法まで決め細かく解説しています
MongoDB Atlas は、M0 Sandboxに関してはスペックは低いですが、1サーバー無料で利用できるので、検証などに最適です。Agent for Knowledge baseで、MongoDB Atlasを使うには、M1以上のスペックになります。
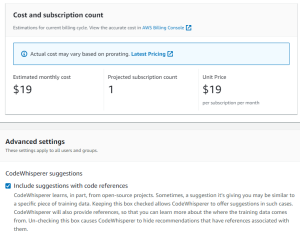
AWS Dev Day 2023のGeneral Sessionでも触れられて、Reject Dayでも、Dev Day のCFPに使っているスクリプト、ほぼCodeWhisperer でコード作成しているなど、注目のプロダクトです。
Github Copilot、Duet AI for code assistance などCode Generateがでています。
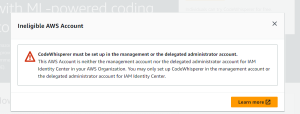
Organizations 配下のAWSアカウントでは、単独ではセットアップできない。
Oraganizationsの管理アカウントから有効化する必要があります
ユーザに紐付いたら、IAM Identify Centerのポータルに下記が追加されます
ここからは、Visual Studio Code(以下VSCode)側の作業になります。
前提として、AWS Toolkit拡張がインストールされていることが前提になります。
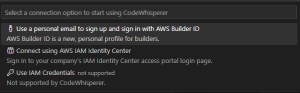
VSCodeから、AWS IAM Identify Centerに接続
Identify Center URL
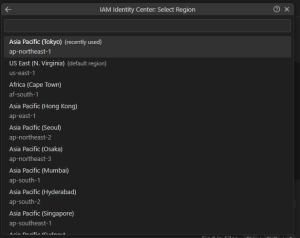
リージョン選択
IAM Identify Centerのリージョンを選択
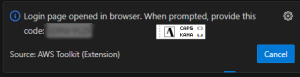
VSCodeの通知ウィンドウに、コードが表示されます
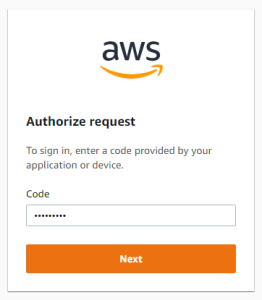
表示されたコードをブラウザの下記に入力
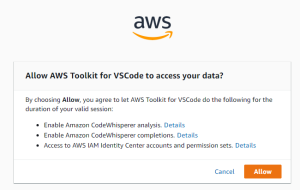
AWS Toolkitからアクセスを許可
これでCodeWhispererガ利用できます。
awk も対応しているようです。
# awk filter for test file
# Usage: ./test.sh < test.txt
awk '
BEGIN {
# Set the field separator to a comma
FS=","
# Set the output field separator to a comma
OFS=","
# Set the output record separator to a newline
ORS="\n"
# Set the input record separator to a newline
RS="\n"
}
{
# Print the first field
print $1
}
END {
# Exit with a success error code
exit 0
}