
BigQueryで公開データとして公開されているNOAA Global Historical Climatology Network の天候データを、エクスポートして、Amazon Athenaで使用してみました。
Column-oriented フォーマットにカテゴリ分けされる Parquetに変換して検証してみました。
ParquentへのConvertはApache Drillを使用
0: jdbc:drill:zk=local> ALTER SESSION SET `store.format` = 'parquet' . . . . . . . . . . . > ; +-------+------------------------+ | ok | summary | +-------+------------------------+ | true | store.format updated. | +-------+------------------------+ 1 row selected (1.655 seconds)
CTASクエリでの変換だと、VARCHARとして扱われてしまうので、カラム毎の型を設定しておく必要があります。それをしないと、Athenaでクエリ実行時、internal errorとなってしまいます。
0: jdbc:drill:zk=local> CREATE TABLE dfs.tmp.`/ghcnd_2016/` AS SELECT . . . . . . . . . . . > id, . . . . . . . . . . . > `date`, . . . . . . . . . . . > `element`, . . . . . . . . . . . > CAST(`value` AS FLOAT) AS `value`, . . . . . . . . . . . > mflag, . . . . . . . . . . . > qflag, . . . . . . . . . . . > sflag, . . . . . . . . . . . > `time` . . . . . . . . . . . > FROM dfs.`/tmp/ghcnd_2016_ja.csvh`; SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. +-----------+----------------------------+ | Fragment | Number of records written | +-----------+----------------------------+ | 0_0 | 174292 | +-----------+----------------------------+ 1 row selected (3.755 seconds)
気象観測所のデータはCTASクエリによる変換で済ませています。
ParquentのファイルをS3にアップロードし、Athenaのテーブルを作成します。
CREATE EXTERNAL TABLE IF NOT EXISTS athena_test_1.ghcnd_2016 ( id string, date string, element string, value float, mflag string, qflag string, sflag string, time string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1' ) LOCATION 's3://athena-test-data01/parquent/ghcnd_2016/';
CREATE EXTERNAL TABLE IF NOT EXISTS athena_test_1.ghcnd_stations ( id string, latitude float, longitude float, elevation float, state string, name string, gsn_flag string, hcn_crn_flag string, wmoid int ) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1' ) LOCATION 's3://athena-test-data01/parquent/ghcnd_stations/';
データ数は以下となっています。
| ghcnd_2016 | 174292 |
| ghcnd_stations | 100820 |
Amazon Athenaの実行結果
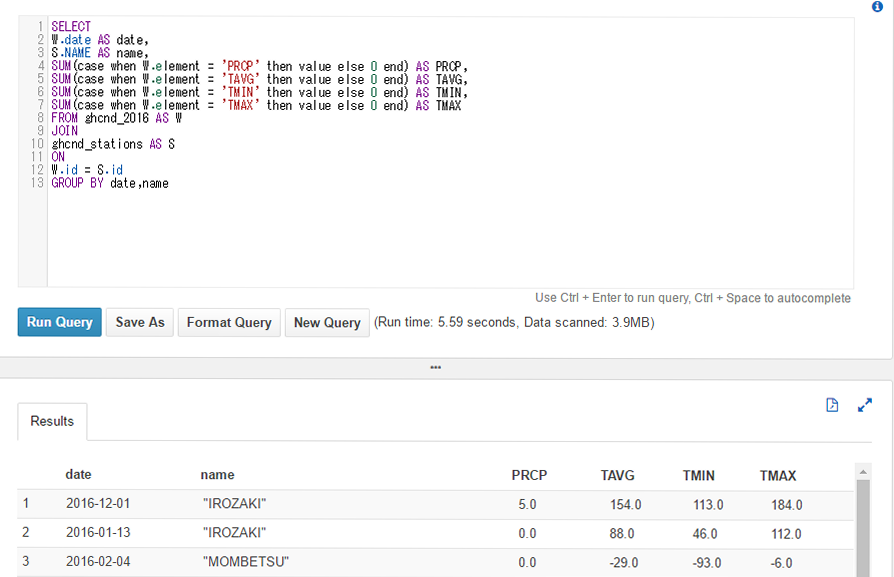
Row-orientedのCSVファイルの結果。データスキャンサイズが、Column-orientedの場合に比べて、4倍。
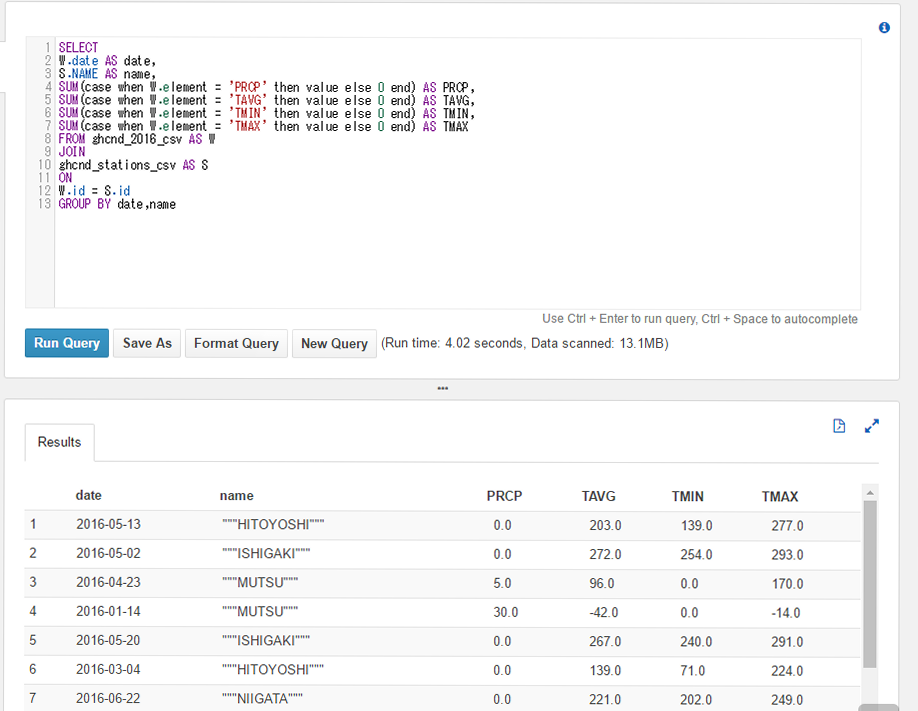
BigQueryでの実行結果
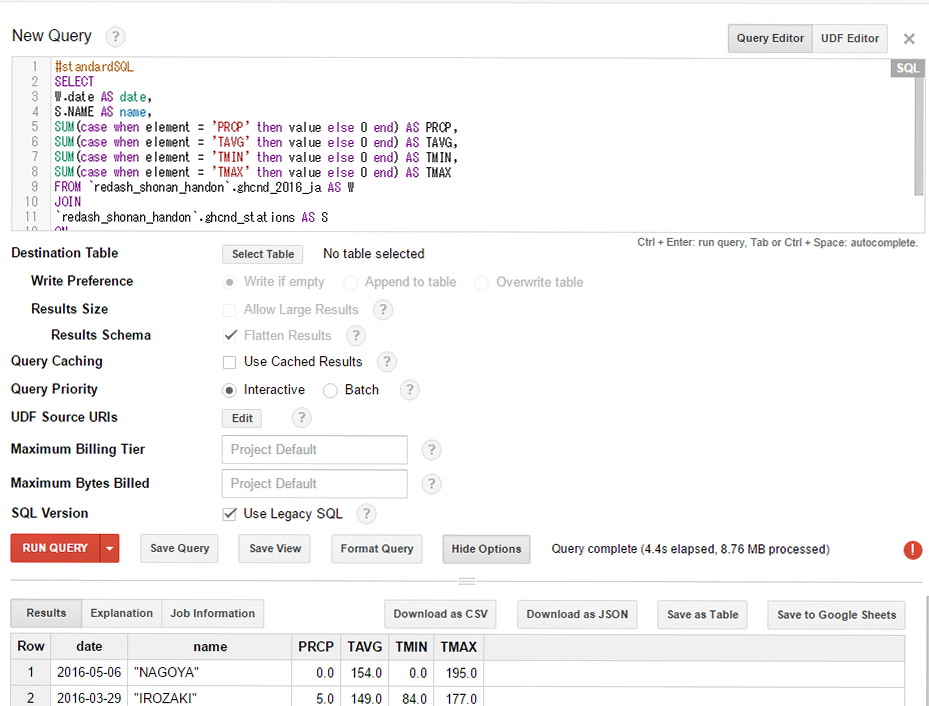
BigQueryと比較して、2秒差、スキャンサイズがBigQueryの1/2の結果になりました。