Momento webhookは一回は送信するが、再度送信する必要があるが、EventBridgeのRetryで対応できるか
Momento will attempt to deliver an event to your webhook one time. If an event is not received by your endpoint, the publisher is required to send the message again.
V8 ↗ orchestrates isolates: lightweight contexts that provide your code with variables it can access and a safe environment to be executed within. You could even consider an isolate a sandbox for your function to run in.
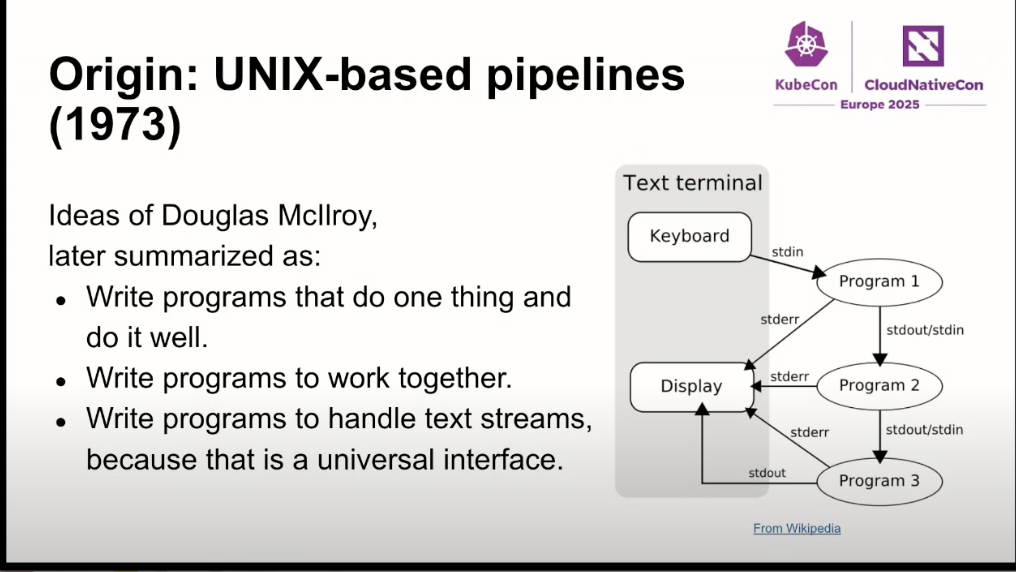
what we’re doing here is we’re actually building like we said more reliable systems out of less reliable Parts. So this means the bottom of the pyramid has fewer nines than the top.
All of the VMS that are running that system have two ninths. All right, the discs that that are running that are holding your data for Gmail have one night.
One region tends to fail at a time, so if you use two zones, This one has 99.9. This one has 99.99. They’re a different set of 99.9. Right. So it’s very unlikely that they will both fail at the same time. So this means that when a failure happens in one of the zones you can just run away, you do not have to debug it.
We’ll be talking today about Managing life cycle of the operating systems in a deterministic way.
Imagine resolving all the dependencies for packages downloading. All of these packages and deploying them onto the host would take enormous amount of time. What we are proposing is changing to this mechanism which sudendra is going to work.
Recording in progress. Awesome. Hey everyone. Welcome. I know more folks will be joining but we only get silent. We had a tight schedule.
Yo, welcome to welcome back into Tiny B's practice. Public data launch webinar. My name is kanyan and I'll lead a tiny B park mctavia. I'll be host for today's session.
Dollars e. And I will cover a few slides about the Innovations that we have in this launch and do a part-time. After the launch part is done, we will have a panel discussion. Painfuls from AW News to Lama index and pink cap. They will go into how to use this air Technologies.
Specifically Vector search to build some commercially viable applications. Uh after that we'll have another demo going to details of one such interesting use case and with that I will conclude the session. Forget that, let me hand it up to Shen, then please take it away. So yeah, welcome everyone.
Uh, I'm Xing and I hope you can hear me clearly. I'm the product manager of Thai DB cloud and AI today. I'm excited to share a significant leap forward in our database technology. The public battle for our KDB sectors vectors search. This is not just a new feature. It's a transformation bringing together AI at the most advanced distributed database in a seamless.
Powerful way. So let's first talk about why we are doing Market search in tidy B. So in today's generative, AI Technologies, we are driving a demand of advised data, handling capabilities, every day every organization and an every large language model is generating and processing, vast amounts of the data, either extraordinary space, the challenge of many organizations managing this search efficiency, ensuring quick access analysis and the ability to scale or demand all at a lower cost kind of select research addresses.
This need by providing a unified database solution that simplifies your Tech stack by handling, both traditional and Ai workloads, this eliminates the need for separate systems to handle different types of data operations, reducing the capacity, and the enhancing the performance plus Thai device architecture. Reassures that your data grows whether in volume velocity or variety your systems.
Perform a skills. You effortlessly. This is crucial for pieces that you that needs to stay competitive in today's fast pacing generative, AI market, furthermore, our SQL compatible Vector, search leverage, your existing SQL expertise to seamless integrate your business. With AI or vector functionalities. This is not just a simplifies, the learning curve, but also empowers your teams, your, your Engineers, your, you know, dpas to perform sophisticated data or operations using familiar tools.
Let's have a quick gallon of the technical part of our Innovation. Thai DB introduces new Vector, search marketer data type and this and the similarity search. Indexes enabling you to store data the victory values together. Seamlessly thinking about a real generative, AI chatbot development. You can just leverage tidy, B, to store your operational data, document data Knowledge Graph and messages store C plus Vector data data.
Search Vector data in just one database, these capabilities can efficiently. Simplifies the capacity data, you know, operations and enable you just focusing on the value of your data. Furthermore, Thai DB Soaker search build on half of our native columnar storage architecture which is tidbit another famous open source project by Pinkard.
This ensures racket search performance in essential social. Real-Time demands for modern UR applications. This design, not only boosts the efficiency, but also significantly improve the query execution speed allowing, you just, you know, building applications figuring out data inside faster and more reliable. Um, so actually uh, before our public beta.
Uh, in March, we launched the private battle of the high DB vector search. So, over the past three months, we have seen an incredible engagement more than 600 users from a diverse range of Industries. Have joined us bringing their valuable unique perspectives and feedback to us to the product team, to the, to our community.
We heard how Thai DBS. 01 AI solution, could simplify their technology stacks making their backend management. Back-end service is more straightforward and streamlined. All the operational machine work are less consuming. This Simplicity brings the power raised the power of the Thai. DB also brings lower costs for their long-term solution, allowing our developers focusing more on Up in The Cutting Edge generative, AI applications with a familiar SQL interfaces without getting into the, you know, super complicated data management tasks.
So, this is actually what we heard from our users. The database you need is the database. You are using is the best Vector database. And this is also the commitment from us at idv. At Inca our Innovation, uh, and the powerful capabilities of our market search technology making idb the one choice for your business in the year of AI.
So, With that, let me put this into some of the uh, you know real demo practices. Um, so uh, let me share my screen, uh, with the our Cloud management portal. So, assume you are a new user coming to a tinydb, you just type, you know, iredbcloud.com, you will be, uh, you know, direct to this signal page.
I will just sign up with my Google account. I clicked my account. And it's just in a few seconds. Uh you will be assigned a new entire DB service cluster and inside this cluster uh you know there are multiple functionalities for you to navigate to learn about the Thai DB and build, you know, regular uh you know uh applications or generative AI applications with the vector search.
So as a developer, my first step is definitely to connect my database. So here you can see uh, you know, we support different types of drivers, clients for you to connect to, but today I'm going to do a demo. We're seeing uh, you know, the Google collab. Is a notebook.
So, the tasks I'm going to perform here is to, you know, input, some of the, uh, you know, text data, convert them to embeddings and later using Vector, search to figure out the answer, uh, for semantic search answers result, uh, for my questions. So I'm zooming a little bit so that the font size will be bigger.
So you can see uh, in Google Cloud. Uh, you know, I have to say, for everyone's time, I have already, put some of the secrets here uh, to really connect that, uh, you need to install those libraries, you have to, you know, uh, put the database connection streams with username password and everything.
And uh and at that we'll uh give you the permission to connect. So here, I guess I'm not initialized the notebook. Uh, it takes some time to you know uh install all the drivers. While I'm doing that, I'm going to recreate the connection and copy paste, the data into the Into the secret part.
So I'm going to you know, regenerate the password and put it here. And also the rest of the part, you can see the DB name, the Thai DB, host the part, and the username, and to save everyone's time, already put it here. You can simply copy paste and just make it happen.
Uh so to make the connection work, uh, you just need to put all the environmental variables reading from the secrets and it should be. Okay. So the next part I'm actually reaching out to the open AI uh to do the embeddings, you can see from the code, I'm using the embedded model here and I'm going to use W with some of the parameters as the L2 distance to generate the older embedules.
I initialized the model and next steps I'm going to, you know, use the model to generate, you know, the embeddings from that. And with that if I run the queries here, I can actually get the answer from open a client. The the questions I'm asking what is high degree?
You can see from the content, I actually put some raw text, IB, content, ikv, content, PD content, those are the three essential parts of our database, you know, from the technology perspective. But if you are searching, what is IDB. If I run the vary, you can see a tin DB is the open source GDC, SQL SQL database.
That's actually the content from the, you know, the the, the, the embedding the raw content. So we start, if I'm going back to my SQL editor, if I'm going to, you know, retrieve the database, uh, you know, the Database record from here. We just you know got some of the table and and with the ID content and the vectoring values here.
If I run the query, I actually run the, you know, Paris and local multiple times. You can see, I have several similar content. It shows the uh, you know, the actual content the embedding data. So the really powerful part is like your traditional data, your structure data, your content.
And the vector, the vector, the embeddings are in the same, you know, table. And your data is much closer, you don't need to manage the multiple systems and everything in just one table. You can easily, you know, retrieve those data processing, those data, build your applications, with really similar six spheres.
So that's just a quick. Hello world of the vector search. And today, we have already have this feature back, public beta on all our Adults regions on IDP servers. So, no matter URL existing 3db service. Customer or you are creating a new account, just coming in to this page and and we have the tutorials building how to let you learn how to use, you know, prefer language being the rich amount of the generative patients.
You have all start here. I just click the button, uh, with all the samples and the tutorials to help you to get started. So, yeah, that's uh, just uh, you know, a quick guidance of the functionality with very simple worker search. So, with that, I'm going to hand over to Kalyanne to talk about what we are also doing in this market.
Awesome. Thank you. Uh, welcome again. So tidy B is more than just practices, right? Why. Because billing applications requires a lot more and we get that, that's why we have been actively partnering with key vendors and players in the AI ecosystem. To bring you a comprehensive solution. So the cluster product native support for big names like AWS and lavline notes, tidally integrates all the foundational language processing tools that you would Whether it's llms chat engines, hosting tools or rag in application development Frameworks or even user experience tools.
So what this means is, you can focus on developing amazing AI applications without worrying about the back-end complexity, similar to the feedback that you've seen from our private data, our Caribbean simplifies the process and accelerates your work. Then, if you go to the next slide, Uh we're reaching the end of the presentation here, so before launching back to search, we did two things.
Internally One, we looked at our mission, right? Our mission is to make the lives of our developers easy. So that is the lens. We have kept rented Center in the development of this capability. Second thing we have done is we have dog food at this app, a lot and used it to actually build a public pacing rag-based chatbot that you'll actually see in the later part of the webinar to improve the developer experience.
Only then we felt good about launching this publicly and making sure you as developers can get to use it. And yeah, see what you can tell. So, uh, with this launch, we've also seamlessly combine, the benefits of cardi B into making practice just scalable and optimate cost efficient right.
First of all, tiny is known for its elastic and infinite scalable nature, right? This is pretty ideal from AI workloads. That can expand at an instant. So that's awesome. Second thing is we have a great Fleet here that chin only showed it is. Perfect for audio. Early needs to try and experience before you actually come back.
The third thing is the fact that nav's open source as always, amazing your indications, And most importantly, the MySQL compatibility, these are all chains on top. Well, hope that got you interested in, trying out theory practices public data. And if you're interested, this is the link and the website is there.
If you want you will get, you can get this tag later too. So by scanning, the according to connect the page to sign up and start your business. Hope you have enjoyed the presentation, as well as the demo now as the time panel, right? So just before we dive into the panel, as we transition to this thing, Uh, we thought of addressing one the main common challenge that development could face, right.
Like you have likely heard a lot about all the latest Innovations in AI and back to search from bunch of vendors. But one thing that we have constantly heard in the pressing question, that that remains is how and where can use these Technologies effectively to put them into right use.
And that's what we want to use. Today's discussion, it aims to it's that Gap. We want to move beyond the theoretical and explore like real world occupations that are not only Innovative but also commercially viable. So our expert Palace from AWS Lama index and Think that will share their insights and experiences highlighting practical use cases and such stories.
We'll also delve into how vector search can transform your AL applications and where the industries are the right for Innovations on. So, with that background, let me start. Pay coming from your position that AWS. You've probably seen a tons of customers Partners. Developers doing some interesting applications with the zit countries, right?
So you want to share some of the interesting ones that you've seen. Yes, for sure. Um, actually a little bit of background what I'm working on and Uh who um I am interacting with. So basically I I came from the So should I get that background? And now I'm working with partners, and customers building applications around data and AI.
So let me actually start from internally within AWS or amazon.com. We know amazon.com is an early adopter of Technologies, like jnai. Probably at that time. We don't even call it genai. But we know on our amazon.com website, their Technologies on reviews and probably labelings. We are already adopting that and within AWS our solution, architects and software, developers are proactively developing tools to improve internal operational process and productivity.
Search use cases as like chat box, search knowledge, bases, coding writing and learning docs Etc. Um, I can share some of our publicly referenced Customers and partners success stories. A lonely Planet is a premier travel media company that tested multiple genai Solutions vendors and found AWS Bedrock to be 78.
More cost effective in their, travel use cases further to that, they were able to generate experiences and itineraries at 80 less the cost of manual creating them. So that is a really successful story. I believe most of our audience have heard of that at our reinvent last year. Um like I said, I'm currently working with our partners Building Solutions around data and AI.
I can share a story of a partners that I work close with. Our partner named publicist Sapien. They have a genai solution, which is public listed called, ask Bondi, it's hosted on AWS. So it's one of a groundbreaking solutions to power gen Ai and let their customers to deploy use cases in a matter of days or weeks from understanding, from the starting point.
So, customers can really focus on their business, differentiated applications as opposed to deal with a lot of like manual overhead. So there are some of the the stories of their success story with their end customers because our partners are Uh, working. With customers deliver values. Faster, they work for a global farmer pharmaceutical company, creating personalized, marketing content, and skill and deploying the first use case within just two weeks.
And they also worked with a North America retailer. Rewriting product descriptions to drive increased engagement using existing product details customer reviews and brand guidelines and tons of highlighting the most important product features. They also worked with uh, invest investment advisor. They quickly identify products and services to recommend to customers with multiple retrieval.
Augmented, Enterprise search solution, basically, from a very sophisticated knowledge base, so we can see customers Up and our partners and also internally within AWS. We are innovating at a speed that we haven't seen before. So definitely I would say a technology that changing the the world
I think I'll be able to call you. Sorry, that's right. My bad. Thanks for Uh, learning now to you before we dive into some of the interesting applications and so on, right? Like a lot of my index has been at the Four Point of the EA Landscape. We've seen all the things.
So the one thing that we have been getting a lot is retrieval augmented generation and how it's gaining a lot of popularity. So first of all, for maybe just can't set the context initially briefly, what it is and what folders Lama and explain it. Excuse me. Um, Still retrieval.
Augmented generation is a solution to a bunch of problems when trying to get. Llms to answer questions about data. Um, The fundamental problem is that obviously llms are trained on a mountain of data, but they're not trained on your data. You the thing that you want to, uh, Answer questions about is the is the data that lives in your company.
Uh, and that data lives in databases. It lives in unstructured files. It lives in. You know, power points and PDFs and slack messages. Um, So fundamentally. If you want to be able to answer questions about that, you have to give that information to an lln. Um, you could try doing it by fine-tuning, an LLM with your data.
Um, but that is uh slow and expensive. And you're not going to be able to uh, you know, refine-tune your model every day to keep up with the new data that you're adding to your database. Uh, so you need a real-time solution and rag provides that solution. What you do in retrieval augmented generation?
Is you first look for data that is relevant to your query and you provide that to the lmm Um an obvious question is you know, if we've got company data? Why don't we give all of our company data to the LR? The answer is if it's just too expensive to do that every single time you have, you know, the average llm has Uh, a, you know, a token when an input token window of Uh, you know, maybe a hundred thousand tokens right now, but you probably have tens of millions of tokens worth of data in your company.
So it couldn't possibly fit into the context window and even if you had an infinite context window, you wouldn't want to because you'd be uploading all of this irrelevant data. Every single time to answer. What might be a very simple question. Um, So instead what you do is you use Vector search, you use, uh you use an embedding model to turn your data into numbers Uh, and then you can use Uh, the same embedding model to turn your query into numbers.
You put all of those numbers into a big database and you can use relatively simple, mathematical operations to locate numbers that are close to each other in the vector space. Um, that is the fundamental Insight. That led to retrieval augmented generations that you could use vector search in this way to search by meaning rather than by keyword.
Um, So, like I said, Retrievalignant degeneration, it sells the limited context window problem it solves real-time data. It allows for attribution because you know that the context that you provided To the other line was this, you know, particular set of documents just before the question was answered. So, you know, the answer is that those documents?
Uh, which can be a big part of The solution. Um, and finally There's accuracy. Um, you are avoiding hallucinations. Um, simply by using this technique by giving the giving the llm your data at the time of the query and saying, use this data that I just gave you and only