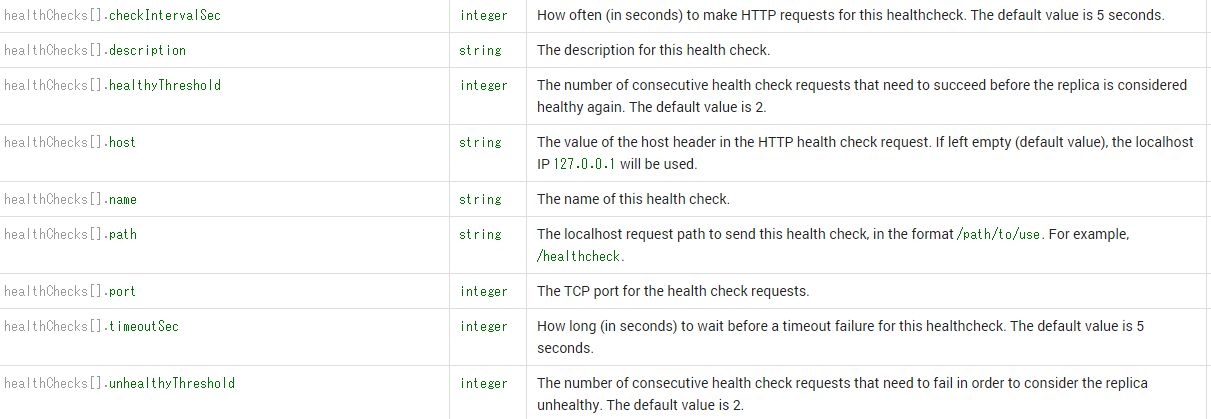
Google Compute Engine のLocal SSD計測結果です。以下に記載されている情報です。
https://cloud.google.com/compute/docs/local-ssd#replicating_local_ssd_performance
NVMEに対応しているのは、現状Debian v7のみです。まずインスタンス起動から
NVMEのCentOS系OS使えるようにならないか。gcloud compute images create から、現時点ではNVMEイメージ作れなそう。
gcloud compute instances create local-ssd-instance-nvme \ --machine-type n1-standard-8 \ --zone asia-east1-b \ --local-ssd-count 2 \ --local-ssd-interface NVME \ --image nvme-backports-debian-7-wheezy-v20140926 \ --image-project gce-nvme
-local-ssd-count 2としたので、google-local-ssd-0、google-local-ssd-1のデバイスが作成されました。
# /usr/share/google/safe_format_and_mount -m "mkfs.ext4 -F" /dev/disk/by-id/google-local-ssd-0 /mnt/ssd0
300GBのSSDディスクが使用可能
# df -h /mnt/ssd0/ Filesystem Size Used Avail Use% Mounted on /dev/nvme0n1 369G 67M 351G 1% /mnt/ssd0
# mv blkdiscard /usr/bin
# blkdiscard /dev/disk/by-id/google-local-ssd-0
- full write pass
sudo fio --name=writefile --size=100G --filesize=100G \ --filename=/dev/disk/by-id/google-local-ssd-0 --bs=1M --nrfiles=1 \ --direct=1 --sync=0 --randrepeat=0 --rw=write --refill_buffers --end_fsync=1 \ --iodepth=200 --ioengine=libaio
WRITE: io=102400MB, aggrb=572807KB/s, minb=572807KB/s, maxb=572807KB/s, mint=183059msec, maxt=183059msec
100G書き込みのに、3分(=183059msec)
- rand read
sudo fio --time_based --name=benchmark --size=100G --runtime=30 \ --filename=/dev/disk/by-id/google-local-ssd-0 --ioengine=libaio --randrepeat=0 \ --iodepth=128 --direct=1 --invalidate=1 --verify=0 --verify_fatal=0 \ --numjobs=4 --rw=randread --blocksize=4k --group_reporting
READ: io=23317MB, aggrb=795648KB/s, minb=795648KB/s, maxb=795648KB/s, mint=30009msec, maxt=30009msec
100Gランダムリードで、0.5分(=3009msec)
- rand write
sudo fio --time_based --name=benchmark --size=100G --runtime=30 \ --filename=/dev/disk/by-id/google-local-ssd-0 --ioengine=libaio --randrepeat=0 \ --iodepth=128 --direct=1 --invalidate=1 --verify=0 --verify_fatal=0 \ --numjobs=4 --rw=randwrite --blocksize=4k --group_reporting
WRITE: io=16667MB, aggrb=568777KB/s, minb=568777KB/s, maxb=568777KB/s, mint=30007msec, maxt=30007msec
100Gランダムライトで、0.5分(=3009msec)
n1-standard-8相当のm3.2xlarge、Ubuntu 14 HVMでもインスタンスストレージにSSDが使えるので、試そうとしましたが、full write passやってみましたが、時間かかり過ぎるので、なんかおかしいと思い、調査中ですので少々お待ちを。