先日のJAWS-UGアーキテクチャー専門支部#2に議論参加側で参加してきました。
Blue-Green deployment パターン(EC2)実装編の叩き台
Blue-Green deploymentとしては、ELBによるもの、DNSによるもの実装としては2つある。
Opsworks、ElasticBeanstalkは、DNSベース。
Blue-Green Deploymentとは異なりますが、Rolling Updateの方法も。過去Rolling Updateの記事を参考までに。
今回は、Ec2のBlue-Green deploymentの話でしたが、Docker、No EC2の場合もあり、幅広くなりそう。
Lambda + API Gateway
受け付ける元がIoTデバイスの場合、100%の許容は必要ないのでは。Kinesisとかバッファリングできるので、少々のダウンとか許容できる
API Gatewayのベストプラスティス
Deploy APIで、ステージング環境(Stage)を作成できるので、Stage→ProductionでAPI GatewayのDeployment管理はできる、ただ、Lambda等組み合わせるので、こちらも考慮する必要があるか。Inheit from Stageで/(production)にoverrideも。
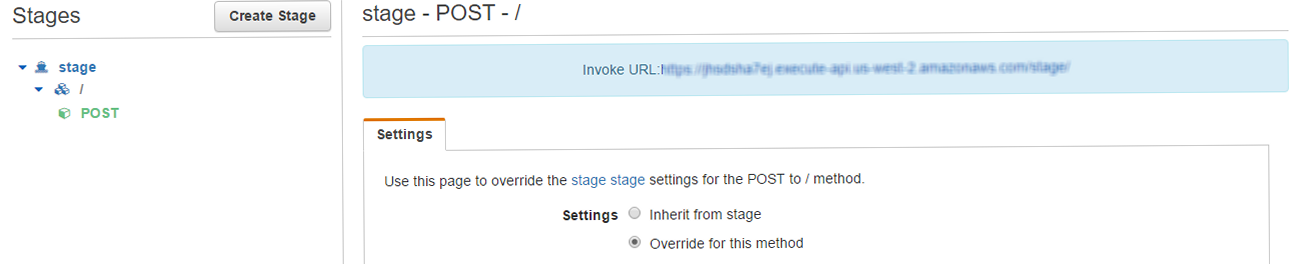
API Gatewayはプロトコル変換が可能。Lambdaを使うと待機リソースが不要。
CodeDeply
デプロイ方式の議論から
- AMI
- userdata (cloud-init)
- Chef/Ansible
Enterpriseの現場では、一番のAMIデプロイが多い。事実、tomcat、Apache等ミドルを入れ込んだ数種類のAMIを用意して、用途に合わせたサーバーを構築するケースもあります。AutoScalingの際、userdataがLaunch Configurationに組み込まれているので、userdata scriptで修正が生じた場合、Launch Configurationから作り直さなければならない。今後のアップデートを期待したい。
メリット
- WebUI
- AutoScaling時の自動適用
デメリット
- ソースが、S3、githubのみ。
- gitlab等プライベートリポジトリへは未対応。
- Internetへのアクセスが必要
- S3のみに限定されているVPC Endpointの他のCodeCommit、DynamoDB等へ対応が待たれる。
CodeDepolyは開発環境で使うのいい?
DynamoDB Streams、Lambdaを使ったアーキテクチャーをまとめていければと思います。
次回はEc2を前提としないクラウドネイティブなCDP 10/15になります。